August 27 Big Model Daily Collection

[August 27 Big Model Daily Collection] News: OpenAI, Adobe and Microsoft support California’s mandatory AI content watermarking bill; KDD 2024 Chinese team makes a shining debut;
OpenAI, Adobe and Microsoft support California’s mandatory AI content watermarking bill
Link: https://news.miracleplus.com/share_link/38717
OpenAI, Adobe and Microsoft, three major technology companies, expressed support for California’s upcoming AB 3211 bill, which requires technology companies to mark AI-generated content. The bill requires watermarks to be added to the metadata of AI-generated photos, videos, and audio, and requires large online platforms (such as Instagram or X) to identify AI-generated content in a way that ordinary viewers can understand.
Background information: The initial version of AB 3211 was opposed by trade groups representing large software manufacturers such as Adobe and Microsoft, who considered the bill “unworkable” and “overburdensome.” However, after the bill was revised, these companies changed their attitude and expressed support. These technology companies are members of the Content Provenance and Authenticity Alliance (C2PA), which helped create a widely used AI content identification standard
KDD 2024 Chinese team shines
Link:https://news.miracleplus.com/share_link/38718
The KDD 2024 conference was held in Barcelona, Spain, attracting top scholars and corporate representatives from around the world to showcase the latest technological achievements in the field of data science. The Chinese team performed well, and the research results of universities and companies such as Tsinghua University, Alibaba, and Squirrel Ai were included, showing China’s leading position in the field of data mining.
The conference covered multiple fields such as data mining, knowledge discovery, and predictive analysis, and deeply explored the application trends of emerging technologies in the education and financial industries. Squirrel Ai represented Chinese technology companies in the fields of generative artificial intelligence and educational technology innovation.
Conference highlights included keynote speeches and roundtable discussions, where experts discussed cutting-edge topics such as the cognitive ability of large language models (LLMs), the symbiosis of AI and the natural environment, and the application of AI in education. In particular, the practice and exploration of the Chinese team in the field of artificial intelligence education have received widespread attention and recognition.

ByteDance Establishes Big Model Research Institute
Link:https://news.miracleplus.com/share_link/38719
ByteDance is secretly preparing to establish a big model research institute and is actively recruiting top AI talents, indicating that big models have become the company’s strategic focus. People familiar with the matter revealed that external AI experts have joined the institute. In addition, Qin Yujia, founder of the original Xuzhi Technology, and Huang Wenhao, a core member of the original Zero One Everything, have also joined ByteDance’s big model team, although it has not yet been clarified whether they are affiliated with the newly established institute.
ByteDance has gradually disclosed the progress of big models since last year, launched the self-developed underlying big model “Skylark” and AI dialogue product “Doubao”, and established an internal project Flow focusing on AI applications. With the continuous expansion of AI products at home and abroad, ByteDance began to introduce more talents from outside, changing its previous practice of relying mainly on internal business lines. As a senior expert in the field of AI, Huang Wenhao has extensive research and application experience in Microsoft Research Asia and Zhiyuan Research Institute. His joining ByteDance further strengthens the strength of its large model team.

Dilemma of Google-affiliated AI startups
Link: https://news.miracleplus.com/share_link/38720
This article explores the dilemma faced by AI startups founded by former Google employees when facing competition from large technology companies. Many Google-affiliated AI startups have been acquired or faced numerous challenges within just a few years of their establishment, due to the lack of business operation experience of founders with academic backgrounds, the high cost of AI development, and the change in investors’ attitudes. The article also lists several AI companies that are considered to be possible acquisition targets, and analyzes their current status and challenges.

Large model chips bombard Hot Chips top conference
Link: https://news.miracleplus.com/share_link/38721
At the 2024 Hot Chips conference, AI chips became the focus. IBM, FuriosaAI and other companies demonstrated innovative AI chips, especially FuriosaAI’s second-generation data center AI chip RNGD, which is designed for large model reasoning. RNGD uses TSMC’s 5nm process, with high energy efficiency, programmability and 256MB on-chip SRAM. Its performance exceeds the current leading GPU, especially when running large language models such as Llama 3.1. IBM released a new generation of Telum II processors with built-in AI accelerator Spyre, and also demonstrated the ability to run AI models on mainframe processors. FuriosaAI emphasized the advantages of its chips in energy efficiency and cost, saying that it solves the practical problems of large-scale AI reasoning in data centers. TCP architecture and tensor contraction processor (TCP) technology are the core of RNGD, providing efficient data reuse and computing power, making it a strong competitor to replace traditional GPUs.
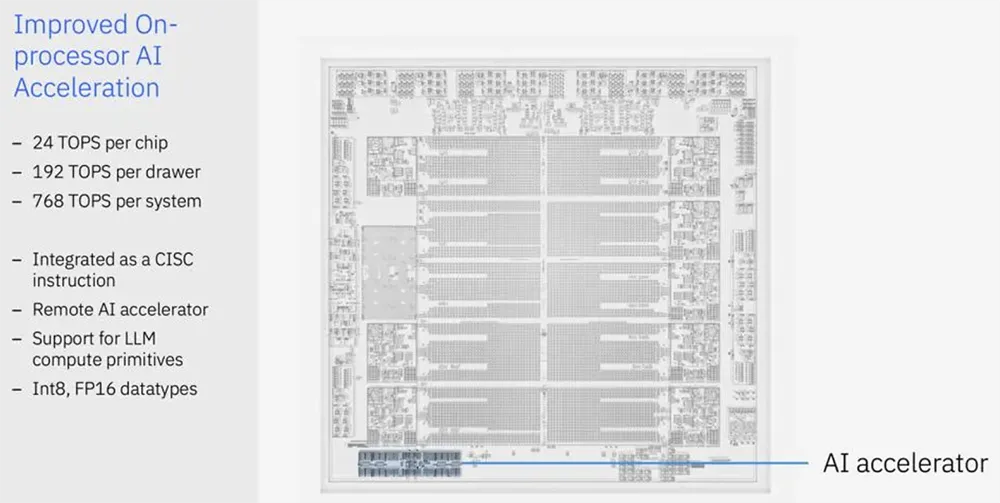
HotChip2024-Day1: AI accelerator chip
Link:https://news.miracleplus.com/share_link/38722
On the first day of HotChip 2024, major non-cloud vendors showcased their AI accelerator chips. Nvidia’s Blackwell was mainly boastful, without revealing microarchitecture details. AMD MI300X and Intel Gaudi 3 were showcased, and Tenstorrent, FuriosaAI, BRCM, etc. also brought interesting content.
Main highlights:
1. AMD MI300X: Adopts Infinity Fabric Advanced Package to achieve high-bandwidth interconnection. Supports FP8 computing, provides 256MB of Infinity Cache, mainly for reasoning and FineTune applications, benchmarking Nvidia H100.
2. Intel Gaudi 3: Continuing the systolic array architecture, the matrix multiplication engine is 256×256, and AGU is added to improve asynchronous computing capabilities. Introducing RoCE interconnection, supporting 21 Fullmesh ScaleUPs and 3 ScaleOuts.
3. SambaNova SN40L: Increasing memory capacity by expanding DDR and supporting multimodal reasoning. The new generation architecture merges PCU and PMU, improves Tensor processing capabilities, and adopts Mesh/Ring hybrid interconnection structure.
4. Furiosa: Introducing the new concept Tensor Contraction Processor, which is based on Einstein summation symbols for calculations. The PCIe card supports 48GB HBM and uses 2D Mesh on-chip network.
5. Tenstorrent: Using a three-block microarchitecture design, it supports asynchronous access to memory and multiple data access primitives, supports standard Ethernet interconnection and can be extended to any topology.
6. Nvidia Blackwell: Although the microarchitecture was not introduced in detail, it mentioned that the computing scale has doubled and the FP4 format will continue to be promoted. 10TB/s interconnection is achieved through NV-HBI, demonstrating a complex liquid cooling system.
7. IBM Telum 2: A new generation of mainframe processors that integrates DPU and AI accelerators to provide stronger computing and data transmission capabilities.
Overall, the diversified development trend of AI accelerator chips is obvious, and each manufacturer has made breakthroughs in reasoning, FineTune, memory expansion and interconnection technology.

Dialogue with Nexa AI: Two Stanford 95s made a small model that is 4 times faster than GPT-4o
Link: https://news.miracleplus.com/share_link/38723
Nexa AI is a startup founded by two Stanford alumni, focusing on the development of efficient small models, with the goal of building a “side-to-side version of Hugging Face”. The Octopus v2 small model developed by the company achieves a reasoning speed 4 times faster than GPT-4o with 500 million parameters, and has performance comparable to GPT-4, with a function call accuracy of more than 98%. The company quickly attracted the attention of the AI community, has signed contracts with many well-known corporate customers, and has received over 10 million US dollars in seed round financing.
Nexa AI’s new product Octopus v3 has multimodal capabilities, can run efficiently on various edge devices, and supports text and image input. The company recently launched the “Model Hub”, an integrated end-to-end AI development platform, which integrates self-developed and other advanced models, aiming to provide developers with flexible solutions for local deployment and build a complete end-to-end AI ecosystem.
The founder believes that small models have advantages in speed, cost, and privacy protection, and can solve most practical problems. Through the innovative Functional Token technology, Nexa AI solves the problem of small model function calls, making its performance surpass GPT-4o. In the face of competition from large manufacturers, Nexa AI seeks differentiation through technological advantages and platform strategies, striving to become a leader in the end-to-end AI field.
