3月4日大模型日報合集

【3月4日大模型日報合集】CVPR 2024滿分論文:浙大提出基於可變形三維高斯的高品質單目動態重建新方法;計算蛋白質工程最新SOTA方法,牛津團隊用密碼子訓練大語言模型;53 頁PDF廣泛流傳,核心員工相繼離職,OpenAI到底有什麼秘密
CVPR 2024滿分論文:浙大提出基於可變形三維高斯的高品質單目動態重建新方法
連結:https://news.miracleplus.com/share_link/20133
單眼動態場景(Monocular Dynamic Scene)是指使用單眼相機觀察並分析的動態環境,其中場景中的物件可以自由移動。 單眼動態場景重建對於理解環境中的動態變化、預測物體運動軌跡以及動態數位資產生成等任務至關重要。 隨著以神經輻射場(Neural Radiance Field, NeRF)為代表的神經渲染的興起,越來越多的工作開始使用隱式表徵(implicit representation)進行動態場景的三維重建。 儘管基於 NeRF 的一些代表工作,如 D-NeRF,Nerfies,K-planes 等已經取得了令人滿意的渲染質量,他們仍然距離真正的照片級真實渲染(photo-realistic rendering)存在一定的距離。 來自浙江大學、位元組跳動的研究團隊認為,上述問題的根本原因在於基於光線投射(ray casting)的NeRF pipeline 透過逆向映射(backward-flow)將觀測空間(observation space)映射到規範空間(canonical space )無法實現準確且乾淨的映射。 逆向映射並不利於可學習結構的收斂,使得目前的方法在 D-NeRF 資料集上只能取得 30 + 等級的 PSNR 渲染指標。

復旦等發表AnyGPT:任意模態輸入輸出,影像、音樂、文字、語音都支持
連結:https://news.miracleplus.com/share_link/20134
最近,OpenAI 的影片生成模型 Sora 爆火,生成式 AI 模型在多模態方面的能力再次引起廣泛關注。 現實世界本質上是多模態的,生物體透過不同的管道感知和交換訊息,包括視覺、語言、聲音和觸覺。 開發多模態系統的一個有望方向是增強LLM 的多模態感知能力,主要涉及多模態編碼器與語言模型的集成,從而使其能夠跨各種模態處理信息,並利用LLM 的文本處理 能力來產生連貫的反應。 然而,該策略僅限於文字生成,不包含多模態輸出。 一些開創性工作透過在語言模型中實現多模態理解和生成取得了重大進展,但這些模型僅包含單一的非文字模態,例如圖像或音訊。 為了解決上述問題,復旦大學邱錫鵬團隊聯合Multimodal Art Projection(MAP)、上海人工智慧實驗室的研究者提出了一種名為AnyGPT 的多模態語言模型,該模型能夠以任意的模態組合來理解 和推理各種模態的內容。 具體來說,AnyGPT 可以理解文字、語音、圖像、音樂等多種模態交織的指令,並能熟練地選擇合適的多模態組合進行回應。
一句話讓圖片動起來,蘋果發力大模型動畫生成,可直接編輯結果
連結:https://news.miracleplus.com/share_link/20135
現階段,大模型驚人的創新能力持續影響創意領域,尤其是以 Sora 為代表的影片生成技術,更是引領了新世代潮流。 當大家都為 Sora 感到震撼的同時,或許蘋果的這項研究也值得大家關註一下。 在一篇名為「Keyframer: Empowering Animation Design using Large Language Models 」的研究中,來自蘋果的研究者發布了一個可以利用LLM 生成動畫的框架Keyframer,該框架允許用戶採用自然語言提示來創建靜態2D 圖像 的動畫。

計算蛋白質工程最新SOTA方法,牛津團隊用密碼子訓練大語言模型
連結:https://news.miracleplus.com/share_link/20136
來自深度語言模型的蛋白質表徵,已經在計算蛋白質工程的許多任務中表現出最先進的性能。 近年來,進展主要集中在參數計數上,最近模型的容量超過了它們所訓練的資料集的大小。 牛津大學(University of Oxford)的研究人員提出一個替代方向。 他們證明,在密碼子而不是胺基酸序列上訓練的大型語言模型可以提供高品質的表徵,並且在各種任務中都優於同類最先進的模型。 在某些任務中,例如物種識別、蛋白質和轉錄本豐度預測等,該團隊發現,基於密碼子訓練的語言模型優於所有其他已發布的蛋白質語言模型,包括一些包含超過50 倍訓練參數的 模型。

53頁PDF廣泛流傳,核心員工相繼離職,OpenAI到底有什麼秘密?
連結:https://news.miracleplus.com/share_link/20137
一份關於「OpenAI 在 2027 年實現 AGI」的 53 頁 PDF,正在網路上廣泛流傳。 文件來自一個名為「vancouver1717」的 X 帳戶,該帳戶註冊於 2023 年 7 月,只有兩條推文。 最新發布的這個PDF 文件稱,OpenAI“將在2027 年前開發出人類水平的AGI”,“從2022 年8 月就在訓練125 萬億參數的多模態模型”,而且已經“在2023 年12 月完成了訓練”,但是“由於高推理成本取消了發布”。 其中提到,這個模型就是原計畫 2025 年發布的 GPT-5,取消後,Gobi(GPT-4.5)改名為 GPT-5。 內容真實度未知,讀過的人傾向於「不信」,因為許多判斷缺乏專業。 不過這篇文檔裡也提到了去年就曝光的神秘計畫Q*(讀作Q-Star),說法是Q * 的下一階段最初是GPT-6,但已更名為GPT-7(原計畫2026 年 發布)。 也就是說,最近一次會發布的 GPT-5 是原本的 GPT-4.5,真正的 GPT-5 延後為 GPT-6,GPT-6 延後為 GPT-7。 但 GPT-7(Q*2025)的智商高達 145,會在 2027 年之前發布,並將實現全面的 AGI。 而這一切的變動,竟然都與馬斯克的一紙訴狀有關。

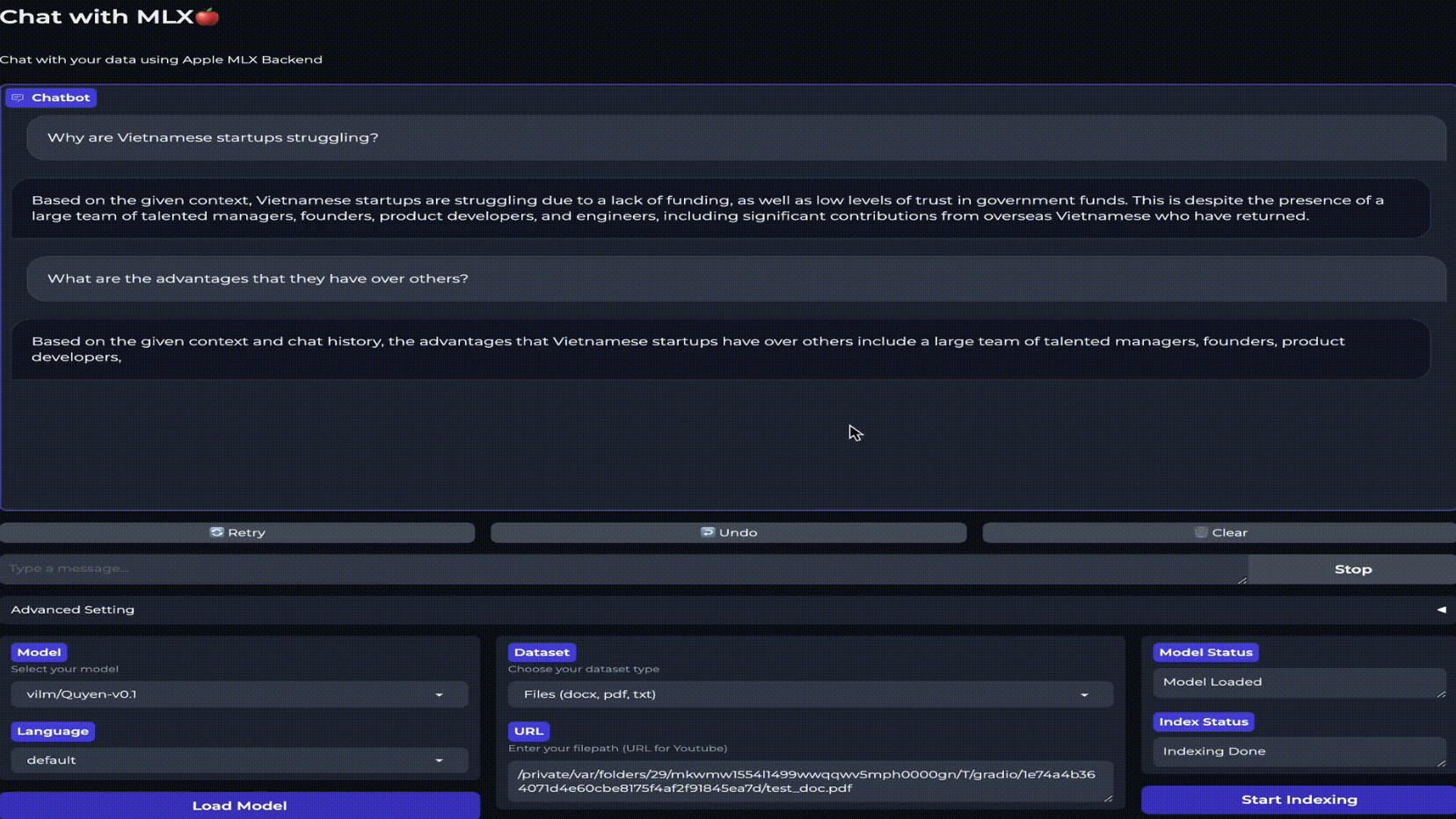
Mac專屬大模型框架來了! 兩行程式碼部署,能聊本地數據,還支援中文
連結:https://news.miracleplus.com/share_link/20138
Mac用戶,終於不用羨慕N卡玩家有專屬大模型Chat with RTX了! 大神推出的新框架,讓蘋果電腦也跑起了本地大模型,而且只要兩行程式碼就能完成部署。 仿照Chat with RTX,框架的名字就叫Chat with MLX(MLX是蘋果機器學習框架),由一名OpenAI前員工打造。 黃院士的框架裡有的功能,例如本地文件總結、YouTube影片分析,Chat with MLX裡也都有。 而且包括中文在內共有11種可用語言,自帶支援的開源大模型多達七種。 體驗過的用戶表示,雖然運算量負擔對蘋果設備可能大了點,但是新手也很容易上手,Chat with MLX真的是個好東西。
Rabbit CEO 談蘋果 AI 新動作與競爭|來回切換 App 很糟糕,R1 是成本與體驗的平衡,99% 新創公司會死掉!
連結:https://news.miracleplus.com/share_link/20140
這是 Rabbit CEO Jesse Lyu 在 CES 後,與 TechCrunch 記者的最新對話。 Jesse 認為,在數位時代,簡化使用者體驗和提高效率是關鍵,透過 R1 設備,他不僅挑戰了現有的作業系統和應用程式生態,更引領了一種全新的人機互動方式。 面對記者關於科技巨頭的競爭,Jesse Lyu 表示,他從10 年前的Y Combinator 學到的第一課就是99% 的創業公司會死掉,一家新創公司毫無疑問是在賭機率,而創業 是一場生存遊戲,最好花時間專注於自己的東西,而不是擔心這個或那個……
