November 7 Big Model Daily Collection

[November 7 Big Model Daily Collection] Special Issue! OpenAI Developer Conference Qiji Daily Team Summary
OpenAI Developer Conference Qiji Daily Team Summary
One sentence summary
OpenAI is becoming the Apple of the AI era: creating AI needs, closed source ecology, GPT store, and hardware under development…
GPT-4 Turbo: Faster, Longer, Cheaper, Multimodal, Customizable
specifically:
* API calls release speed restrictions, double the speed, and support further settings
* Launched GPT-4 Turbo, supporting 128K context, about 300 pages of documents, previously 32K
* Reduce the price of GPT-4 Turbo, input is 3 times cheaper and output is 2 times cheaper than GPT-4, to $0.01 and $0.03 respectively
* GPT 4 Turbo can now accept images as input via API and can generate subtitles, classification and analysis
* GPT4 is open to fine-tuning, allowing companies to customize every step and make it exclusive
Some other details:
* Better JSON/function calls.
* Built-in RAG to update training data to April 2023 deadline
* GPT3.5 supports 16k
* Currently, Dall-E 3, GPT-4V and TTS models are included in the API
* Whisper V3 is open source (coming soon in API)
GPT store: Will it become the next Apple store?
The plug-in mall launched by ChatGPT before was relatively moderately popular. I wonder if it can completely ignite user demand this time.
Key points: Build a personal agent without code, support sharing with others and profit from it.
The name GPT is meant to say that this is a customized version of ChatGPT and the user can create a customized version of ChatGPT for his specific task without writing a single line of code.
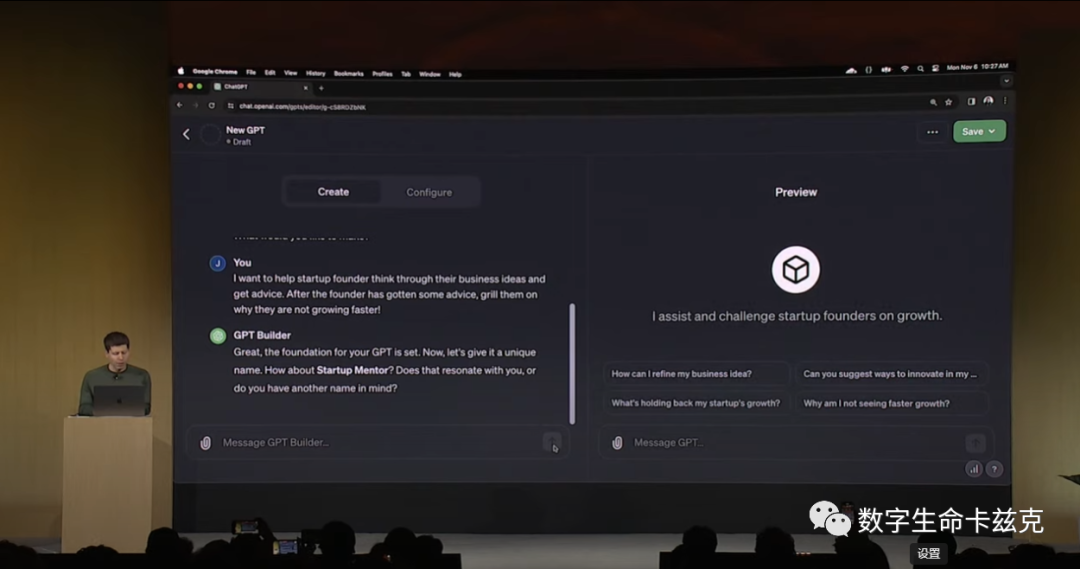
Live practical demonstration:
Moreover, the GPTs created by users can also be shared with friends. Later this month, OpenAI will launch a GPT store, and you can even make money based on the number of people who use the GPTs you create.
Users can connect GPT to the API to perform tasks such as managing databases, email, texting, and more.

Long context:
Many models in China are doing long context. Of course, it is also very easy to do long context now. It just requires one more step of fine-tuning. But being able to accommodate long context does not mean that it can make good use of long context: it cannot correctly recall relevant details, make inferences across articles, and deployment is also a big problem.
Controllability:
Although language models amaze the world with their diverse capabilities, what is really needed when implementing them is controllability and factuality, such as the ability to stably generate JSON, which is also the focus of this update. The implementation may be to limit decoding to ensure that the model is only generated in JSON format, or it may be fine-tuned. The JSON format is not guaranteed to be generated according to the schema.
The second point is controllable output, which can reproduce the content according to the seed.
Sam mentioned that Logprob is back. Logprob helps control the output of the language model in more detail, such as scoring completions and judging whether recall is needed based on likelihood. It can be seen that OpenAI has indeed absorbed feedback from developers.
Is `logprobs` being deprecated, or will it eventually be available for newer models? – API – OpenAI
Agent reasoning:
The Agent displayed by OpenAI uses a mixture of Code and natural language to perform reasoning. This is currently a more reasonable reasoning form for Agent. Code can calculate accurately, while natural language can convey intentions and facilitate people’s verification and understanding.
It can be speculated that one of the uses of Code Interpreter is to collect this kind of reasoning content where natural language and code are intertwined.
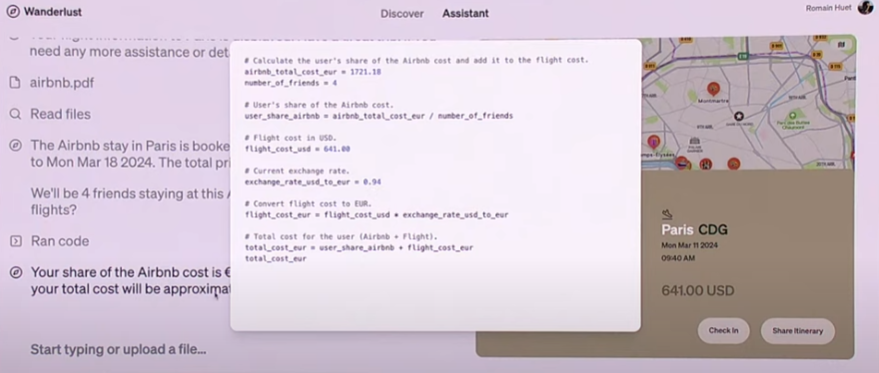
Multimodality:
OpenAI connects text and pictures, text and voice, but of course they have different functions. Pictures can already be used for generation, but voice still mainly serves interaction.
AIGD will have great development, and the Design2Code link has been opened up. Whether it is using GPT-4v directly or using GPT-4v to collect data, the efficiency of developing software will be greatly improved.
RAG:
OpenAI opens Assistant API
In addition, each Assistant can only process up to 20 files, which is a very large limit.
According to the trial on Twitter, OpenAI’s RAG strategy is:
1. The text is divided into blocks by \n.
2. There may be no problem decomposition in the recall strategy, but the number of returned text blocks changes;
3. There is a problem with utf-8 processing;
Of course GPT-4v has certain advantages for processing PDF.

Possible impact on Startup:
There is no need to play with the shallow personalization of Prompt and simple Rag. The platform is very suitable for this kind of thing. jiayuan is about to start pivot.
Deep personalization, including complex recall strategies such as model based, agents with complex interactions with the environment and adjustments to the model will not be replaced in the short term, but may live better. The market for shallow personalization is large, very attractive to users, easy to implement, and of high enough value to the platform; the cost of a market that is too vertical is still too high for the platform, and it will never take advantage of this market until the end of time. By that time, a good startup should be able to establish barriers, whether it is models or data.
In addition, OpenAI as a platform can build user awareness with this shallow personalization. If users feel that their needs are not satisfied, they will naturally seek more vertical services.
Specifically, agents like Sweep should fare better because GPT-4 is cheaper.
Some details:
1. Not using API data to train the model is a very weak constraint (Jack expressed disbelief). It is more valuable to understand the distribution of data through API, and be able to collect and synthesize new data based on this direction;
2. This move of asking Satya is very interesting. It may be to confirm to the outside world that the relationship between the two is still strong;
Thinking: What is the next carrier of AI?
Judging from this developer conference, the functions of ChatGPT are already very powerful. I think the carrier of web pages is no longer suitable for carrying AI. Perhaps OpenAI really wants to develop an OS system of its own, and deploying AI at the system level is a better choice.
Reference:
https://openai.com/blog/new-models-and-developer-products-announced-at-devday