Collection of Big Model Daily on October 23

[Collection of Big Model Daily on October 23] Nvidia and Meta announced major achievements in robots on the same day; adding “markers” to visual prompts, Microsoft and others make GPT-4V more accurate and detailed; AI changes the way of job hunting in Australia , AI recruitment tools are becoming more and more popular;
By adding “markers” to visual cues, Microsoft and others make GPT-4V more accurate and detailed.
Link: https://news.miracleplus.com/share_link/11105
In recent times, we have witnessed significant advances in large language models (LLMs). In particular, the release of Generative Pretrained Transformer, or GPT, has led to several breakthroughs in industry and academia. Since the release of GPT-4, large multimodal models (LMMs) have attracted increasing interest from the research community, and many works have been devoted to building multimodal GPT-4. Recently, GPT-4V (ision) has received special attention due to its excellent multi-modal perception and reasoning capabilities. However, although GPT-4V has unprecedented visual language understanding capabilities, its fine-grained visual grounding (the input is a picture and the corresponding object description, and the output is a box describing the object) capability is relatively weak or has not yet been developed. For example, when the user asked “What object is placed to the left of the laptop on the right?” in the picture below, GPT-4V gave the wrong answer of a mug. When the user then asked, “I’d like a window seat, where can I sit?” GPT-4V also answered incorrectly. After realizing the above problems, researchers from Microsoft, Hong Kong University of Science and Technology and other institutions proposed a new visual prompt method Set-of-Mark (SoM) to solve the problems of GPT-4V in fine-grained visual tasks.

Can your GPU run large models such as Llama 2? Try it out with this open source project
Link: https://news.miracleplus.com/share_link/11106
In an era where computing power is king, can your GPU run large models (LLM) smoothly? Many people struggle to give an exact answer to this question and don’t know how to calculate GPU memory. Because seeing which LLMs a GPU can handle is not as easy as looking at the model size, models can take up a lot of memory during inference (KV cache), e.g. llama-2-7b has a sequence length of 1000 and requires 1GB of additional memory. Not only that, during model training, KV cache, activation and quantization will occupy a lot of memory. We can’t help but wonder whether we can know the above memory usage in advance. In recent days, a new project has appeared on GitHub that can help you calculate how much GPU memory is needed during training or inference of LLM. Not only that, with the help of this project, you can also know the detailed memory distribution and evaluation methods. Quantization method, maximum context length processed and other issues to help users choose the GPU configuration that suits them.

Generate high-definition commercial blockbusters in seconds, e-commerce efficiency directly Pro Max | ArcSoft Technology launches PhotoStudio® AI
Link: https://news.miracleplus.com/share_link/11107
Many of the long-standing and difficult problems of traditional e-commerce, such as “cumbersome processes, long cycles, limited effects, and high costs”, have been solved in one fell swoop. ArcSoft Technology today launched a new innovative product for e-commerce – PhotoStudio(®) AI intelligent commercial photography cloud studio (Beta). According to the official website, ArcSoft PhotoStudio(®) AI intelligent commercial photography cloud studio has opened two versions of services for the first time – clothing version (PhotoStudio(®) AI CL) and product version (PhotoStudio(®) AI MC ).

Analyze over 20,000 bonds with ChatGPT! LTX launches BondGPT+
Link: https://news.miracleplus.com/share_link/11108
LTX, a wholly-owned subsidiary of Broadridge (NYSE: BR), the global financial technology leader, announced on its official website that it has launched “BondGPT+” to analyze more than 20,000 bonds. As early as June 6 this year, LTX launched BondGPT. After receiving praise and positive feedback from a large group of financial customers, it continued to develop BondGPT+ on this basis. BondGPT+ is based on OpenAI’s GPT-4 model and fine-tuned with its own massive amount of high-quality financial data. Compared with the previous generation, BondGPT+ supports company or third-party data integration, content generation preferences, advanced bond search, enterprise-level security and management and other new features.

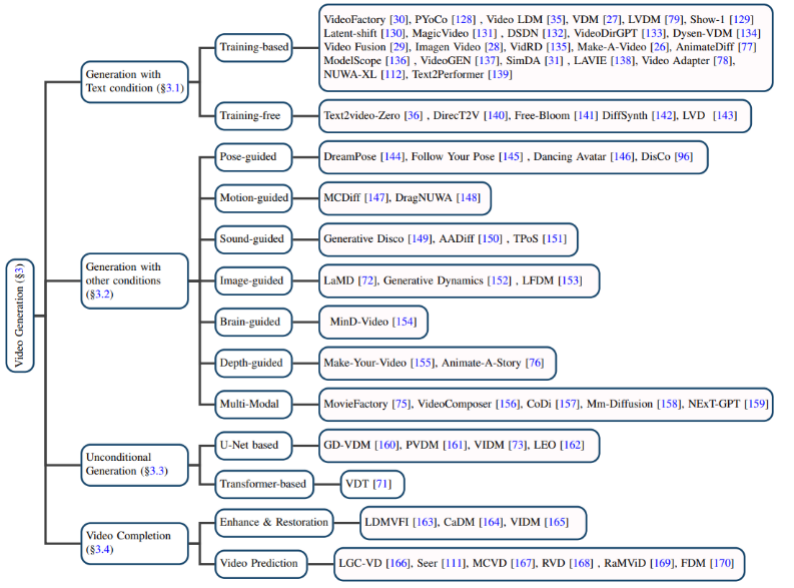
Video diffusion model in the AIGC era, Fudan and other teams released the first review in the field
Link: https://news.miracleplus.com/share_link/11109
AI-generated content has become one of the hottest topics in the current field of artificial intelligence and represents the cutting-edge technology in this field. In recent years, with the release of new technologies such as Stable Diffusion, DALL-E3, and ControlNet, the field of AI image generation and editing has achieved stunning visual effects, and has received widespread attention and discussion in both academia and industry. Most of these methods are based on diffusion models, which is the key to their ability to achieve powerful controllable generation, photorealistic generation, and diversity. However, videos have richer semantic information and dynamic changes than simple static images. Research data shows that since 2022, research work on diffusion models on video tasks has shown explosive growth. This trend not only reflects the popularity of video diffusion models in academia and industry, but also highlights the urgent need for researchers in this field to continue to make breakthroughs and innovations in video generation technology. Recently, the Vision and Learning Laboratory of Fudan University, together with academic institutions such as Microsoft and Huawei, released the first review of diffusion models in video tasks, systematically sorting out the academic cutting-edge results of diffusion models in video generation, video editing, and video understanding.
AI is changing the way Australians apply for jobs, and AI recruitment tools are becoming more and more popular
Link: https://news.miracleplus.com/share_link/11110
Artificial intelligence is becoming increasingly common in Australia’s recruitment sector, being used to screen resumes and conduct preliminary interviews, with profound consequences for job seekers. Although AI has benefits in improving recruitment efficiency, it also raises issues of fairness and discrimination, with studies showing that AI screening of applicants can reinforce biases against women and cultural minorities. Job seekers face a lack of transparency into how they will be assessed in the recruitment process, and Australian law does not clearly require job applicants to be informed of the details of AI screening.
