The blood of developing large models – detailed data engineering with long articles of 10,000 words
The blood of developing large models – detailed data engineering with long articles of 10,000 words
Content introduction
This article takes a deep dive into data engineering for large language models (LLMs) in R&D. The importance of effective data management is emphasized, as well as the use of advanced techniques such as domain-adaptive pre-training, supervised fine-tuning and retrieval enhancement generation to improve the performance of LLMs in professional fields. A key takeaway is the concept of AI BOMs, providing transparency and risk assessment through metadata related to AI training data and model architecture. This article stands out for its comprehensive approach to improving the reliability and performance of LLMs in R&D and is a valuable read for professionals working in the fields of artificial intelligence and machine learning.
Automatic summary
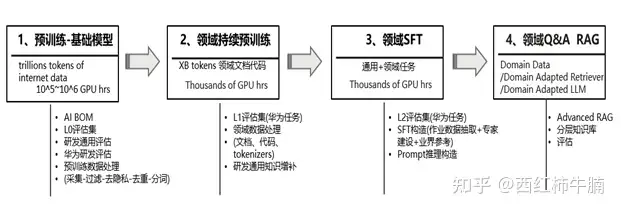
– Data quality is critical to model performance and training efficiency.
– Data management is required in the pre-training and fine-tuning stages to enhance model performance and improve training efficiency.
– The pre-training stage requires training using general text and special text to obtain basic language understanding and generation capabilities.
– In the pre-training data, pre-processing steps such as quality filtering, deduplication, privacy removal and word segmentation are required.
– Domain pre-training can improve model performance through incremental pre-training or domain-adaptive pre-training.
– The fine-tuning phase requires designing the instruction format to suit the specific task.
– RAG technology can improve the quality of responses generated by the model.
– The inference phase requires cue engineering to design cue strategies suitable for specific tasks.
– The concept of AIBOM can improve the transparency and risk assessment of AI training data.
– SFT, RAG and fine-tuning can be used simultaneously to improve model performance and reliability.
Original link: https://zhuanlan.zhihu.com/p/685077556