Collection of big model daily reports on February 2

[Collection of big model daily reports on February 2] A16Z’s latest AI insights | 2023 is the first year of AI video, and there are still these problems that need to be solved in 2024; Two years old, one and a half years of teaching experience: Baby AI trainer is on Science; 2B Parameter performance exceeds Mistral-7B: wall-facing intelligent multi-modal end-side model open source
There are also thieves in large models? To protect your parameters, submit the large model to make a “human-readable fingerprint”
Link: https://news.miracleplus.com/share_link/17446
Pre-training of large models requires a huge amount of computing resources and data. Therefore, the parameters of pre-trained models are becoming the core competitiveness and assets that major institutions focus on protecting. However, unlike traditional software intellectual property protection, which can confirm whether there is code theft by comparing the source code, there are two new problems in judging the theft of pre-training model parameters: 1) The parameters of the pre-training model, especially thousands of The parameters of billion-level models are usually not open source. 2) More importantly, the output and parameters of the pre-trained model will change with downstream processing steps such as SFT, RLHF, and continue pretraining. This makes it difficult to determine whether a model is fine-tuned based on another existing model, whether based on model output or model parameters. Therefore, the protection of large model parameters is a new problem that lacks effective solutions. To this end, the Lumia research team from Professor Lin Zhouhan of Shanghai Jiao Tong University has developed a human-readable large model fingerprint. This method can effectively identify the ancestry between each large model without the need to disclose model parameters. relation.

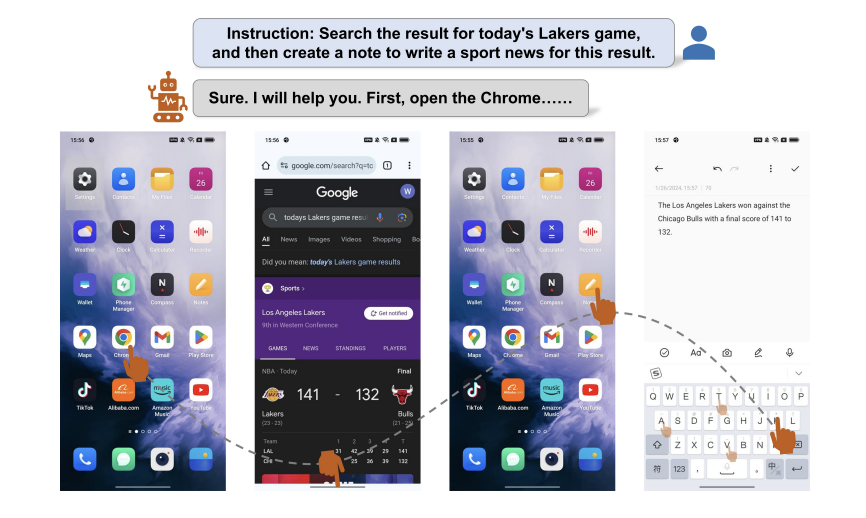
Alibaba’s new Agent plays with mobile phones: he likes and comments on short videos and learns to operate across applications
Link: https://news.miracleplus.com/share_link/17447
The smart body that can control mobile phones has ushered in a new upgrade! The new Agent breaks the boundaries of APPs and can complete tasks across applications, becoming a true super mobile assistant. For example, according to instructions, it can search for the results of a basketball game on its own, and then write a text in a memo based on the game conditions. A latest paper from Alibaba shows that Mobile-Agent, a new mobile phone control agent framework, can play with 10 applications and complete tasks assigned by users across APPs. It is plug-and-play and requires no training. Relying on the multi-modal large model, the entire manipulation process is completely based on visual capabilities, and there is no need to write XML operation documents for the APP.
The four indicators on the metabolism data set reached 94%~98%. The Southwest Jiaotong University team developed a multi-scale graph neural network framework to assist drug research and development.
Link: https://news.miracleplus.com/share_link/17448
In the process of drug development, understanding the relationship between molecules and metabolic pathways is crucial for synthesizing new molecules and optimizing drug metabolism mechanisms. The Yang Yan/Jiang Yongquan team at Southwest Jiaotong University developed a new multi-scale graph neural network framework MSGNN to connect compounds and metabolic pathways. It consists of three parts: a feature encoder, a subgraph encoder and a global feature processor, which respectively learn atomic features, substructure features and additional global molecular features. These three-scale features can give the model more comprehensive information. The performance of this framework on the KEGG metabolic pathway data set is better than existing methods, with Accuracy, Precision, Recall, and F1 reaching 98.17%, 94.18%, 94.43%, and 94.30% respectively. In addition, the team also adopted a graph augmentation strategy to expand the amount of data in the training set tenfold, making model training more adequate.

A16Z’s latest AI insights | 2023 is the first year of AI video, and there are still these problems that need to be solved in 2024
Link: https://news.miracleplus.com/share_link/17449
This is the latest AI video outlook for 2024 released by A16Z partner Justine Moore. Justine mentioned that 2023 will be a breakthrough year for the field of AI video. At the beginning of 2023, public text-to-video models did not exist. Just 12 months later, dozens of video generation products are already in active use, with millions of users around the world creating short clips from text or image prompts. These products are still relatively limited – most generated videos are 3 to 4 seconds long, the quality of the output varies, and issues like character consistency have not yet been resolved. We’re still a long way from creating Pixar-level shorts with a single text prompt (or even multiple prompts!). However, the advancements we’ve witnessed in the video generation space over the past year suggest that we’re in the early stages of a massive transformation, similar to what we’ve seen with the A16Z in the image generation space. We are witnessing continued improvements in text-to-video models, and derivative technologies like image-to-video and video-to-video gaining momentum. To help make sense of this explosion of innovation, A16Z tracks the most important developments so far, the companies to watch, and the remaining fundamental questions in the field.

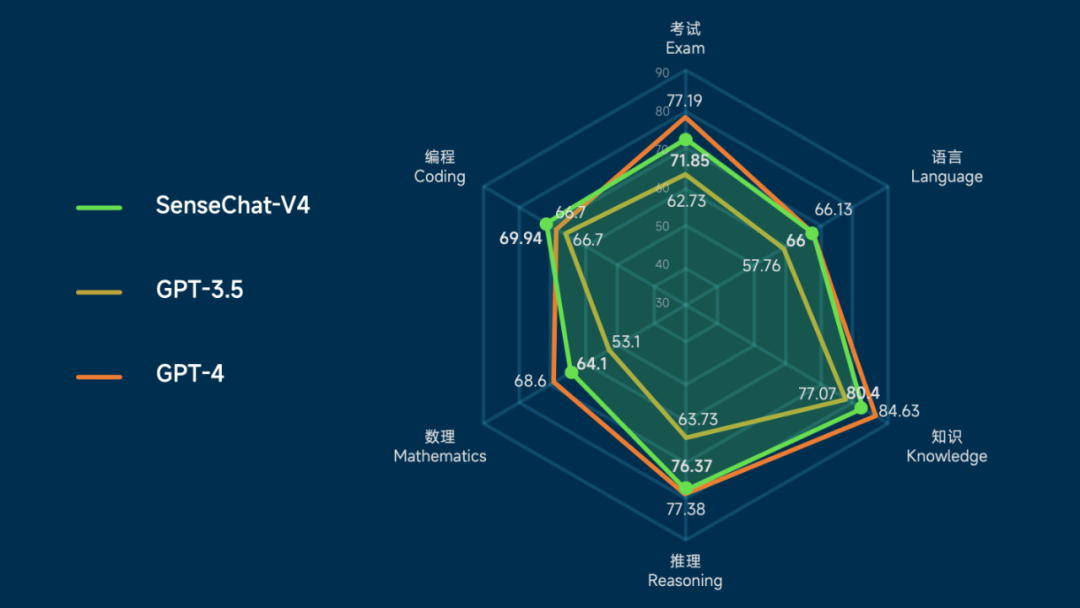
Comparing with GPT-4, SenseTime has significantly upgraded to 4.0, taking the lead in multi-modal capabilities
Link: https://news.miracleplus.com/share_link/17450
SenseTime’s large-scale model system “RiRiXin SenseNova” has just released version 4.0 today. Both language and text capabilities have been fully upgraded, and it also comes with low-threshold implementation tools. The new generation of SenseNova has not only made major upgrades in large language models, Vincentian graph models, etc., and its capabilities in some vertical fields have surpassed GPT-4. It has also released a new multi-modal large model and provided a new version for data analysis, medical and other scenarios. , allowing the general capabilities of large models to be adapted to more fields.
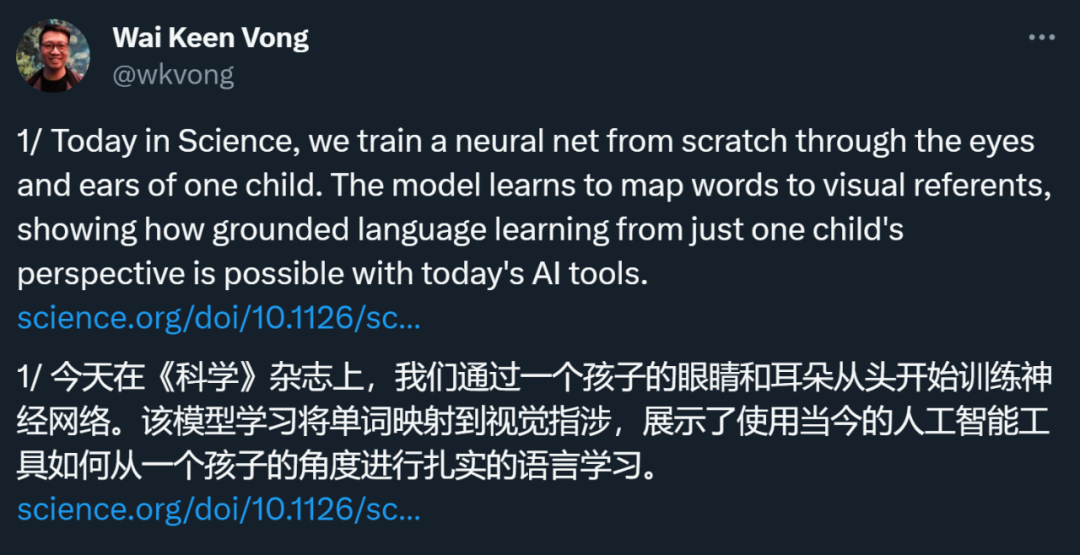
Aged two years old, teaching experience for one and a half years: Baby AI trainer appears on Science
Link: https://news.miracleplus.com/share_link/17451
In public interviews, Turing Award winner Yann LeCun mentioned many times that the learning efficiency of current AI models is too low compared with human babies. So, if you ask an AI model to learn what a baby’s head-mounted camera captures, what can it learn? Recently, a paper in Science magazine made a preliminary attempt. The study found that even with limited data, the AI model can learn the mapping between words and visual referents from 10 to 100 examples, and can generalize to new visual data sets with zero samples and achieve multi-modal alignment. . This shows that using today’s artificial intelligence tools, true language learning from an infant’s perspective is possible.
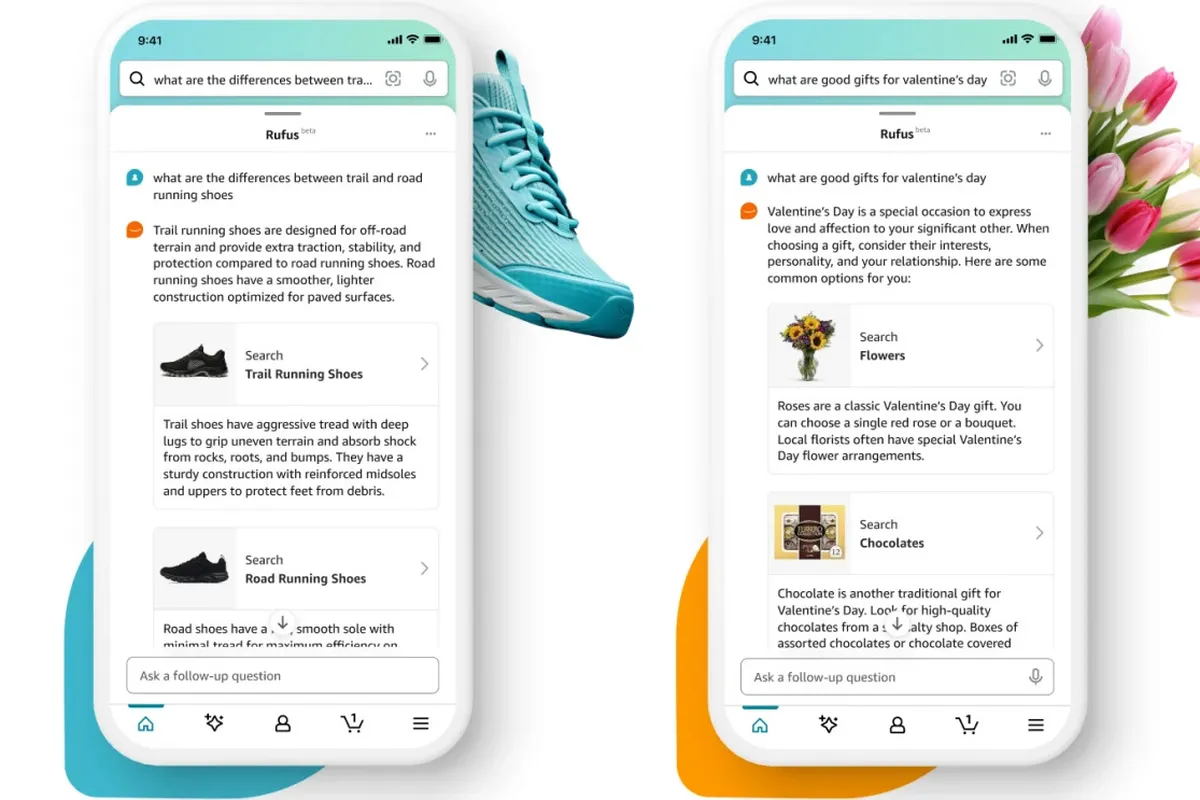
Amazon launches artificial intelligence shopping assistant TRufusJ
Link: https://news.miracleplus.com/share_link/17452
Amazon has launched an artificial intelligence shopping assistant called Rufus, named after the company’s corgi mascot. The chatbot was trained on Amazon’s product library, customer reviews, and information from the web, allowing it to answer questions about products, conduct comparisons, provide recommendations, and more. Rufus is still in beta and will only be available to “select customers” before rolling out to more users in the coming weeks.
2B parameter performance exceeds Mistral-7B: wall-facing intelligent multi-modal end-side model open source
Link: https://news.miracleplus.com/share_link/17453
While large models continue to move towards large volumes, in recent times, people have also achieved results in optimization and deployment. On February 1, Wall-Facing Intelligence and Tsinghua NLP Laboratory officially released the flagship end-to-side large model “Wall-Facing MiniCPM” in Beijing. The new generation of large models is called “performance small steel cannon”, which directly embraces terminal deployment, and also has the strongest multi-modal capabilities in its class. The MiniCPM 2B parameter volume proposed by Face Wall Intelligence this time is only 2 billion, and it is trained using selected data of 1T token. This is a model with the same level of parameters as BERT in 2018. Wall-Facing Intelligence has achieved ultimate performance optimization and cost control on top of it, allowing the model to “leapfrog and defeat monsters.” Li Dahai, co-founder and CEO of Face Wall Intelligence, compared the new model with Mistral-7B, a well-known open source large model in the industry. On many mainstream evaluation lists, the performance of MiniCPM 2B completely surpassed the latter.
