Collection of big model daily reports from February 18th to 19th

[Collection of big model daily reports from February 18th to 19th] In the post-Sora era, how do CV practitioners choose models? Convolution or ViT, supervised learning or CLIP paradigm; Revealing Sora’s technical route: core members are from Berkeley, and the basic paper was rejected by CVPR; Karpathy, who left OpenAI and was unemployed, started a new large-scale model project, and the number of stars exceeded 1,000 a day; NVIDIA The fastest AI supercomputer disclosed for the first time: equipped with 4608 H100 GPUs
In the post-Sora era, how do CV practitioners choose models? Convolution or ViT, supervised learning or CLIP paradigm
Link: https://news.miracleplus.com/share_link/18656
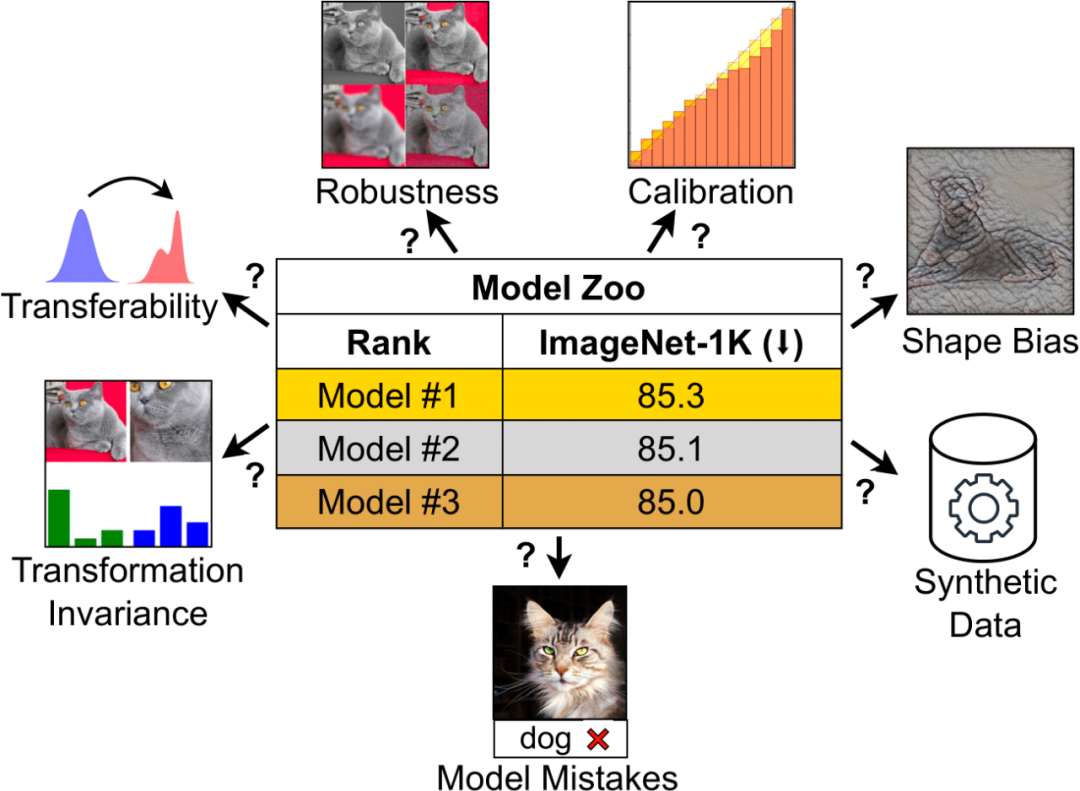
ImageNet accuracy has long been the primary metric for evaluating model performance, and it was what initially ignited the deep learning revolution. But for today’s computational vision field, this indicator is becoming less and less “sufficient”. Because computer vision models have become increasingly complex, the variety of available models has increased dramatically, from early ConvNets to Vision Transformers. Likewise, training paradigms have evolved from supervised training on ImageNet to self-supervised learning and image-text pair training like CLIP. ImageNet cannot capture the nuances produced by different architectures, training paradigms, and data. Models with different properties may look similar if judged solely on ImageNet accuracy. This limitation becomes more apparent when the model begins to overfit the specificity of ImageNet and saturates accuracy. CLIP is a noteworthy example: although CLIP’s ImageNet accuracy is similar to ResNet, its visual encoder is much more robust and transferable. These questions have brought new confusion to practitioners in the field: How to measure a visual model? And how to choose a visual model that suits your needs? In a recent paper, researchers from MBZUAI and Meta conducted an in-depth discussion on this issue.
Let the visual language model do spatial reasoning, and Google is new again
Link: https://news.miracleplus.com/share_link/18657
Visual language models (VLMs) have achieved significant progress on a wide range of tasks, including image description, visual question answering (VQA), embodied planning, action recognition, and more. However, most visual language models still have some difficulties in spatial reasoning, such as tasks that require understanding the location or spatial relationships of objects in three-dimensional space. Regarding this issue, researchers often draw inspiration from “humans”: through embodied experience and evolutionary development, humans have inherent spatial reasoning skills and can effortlessly determine spatial relationships, such as the relative position of objects or estimate distances and sums. size without the need for complex chains of thought or mental calculations. This proficiency in direct spatial reasoning tasks contrasts with the limitations of current visual language model capabilities and raises a compelling research question: Can visual language models be endowed with human-like spatial reasoning capabilities? Recently, Google proposed a visual language model with spatial reasoning capabilities: SpatialVLM.

With 1 million tokens, one hour of YouTube videos can be analyzed at a time, and the “big world model” is becoming popular.
Link: https://news.miracleplus.com/share_link/18658
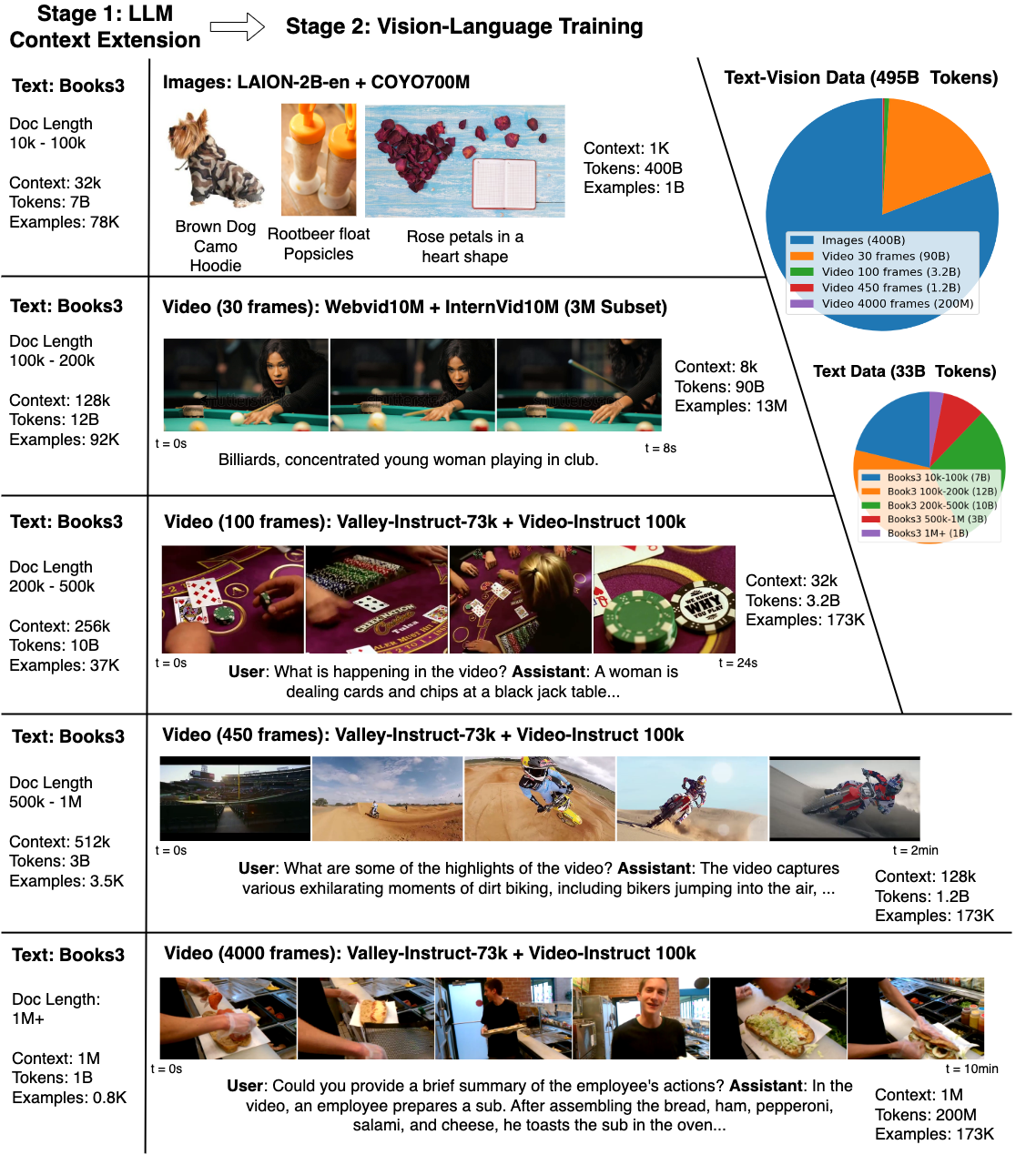
Not only Sora, although large models are developing rapidly nowadays, they also have their own shortcomings. For example, the content in the real world is not easy to describe in language, and the model is very difficult to understand. For example, these models are difficult to handle complex long-range tasks. The emergence of video models alleviates this problem to a certain extent, which can provide the temporal information missing in language and static images, which is very valuable for LLM. As technology advances, models begin to gain a better understanding of textual knowledge and the physical world, thereby helping humans. However, learning from tokens from millions of video and language sequences is challenging due to memory constraints, computational complexity, and limited datasets. In order to address these challenges, researchers from UC Berkeley compiled a large data set containing various videos and books, and proposed the Large World Model (LWM), which uses RingAttention technology to perform scalable training on long sequences. Gradually increase the context size from 4K to 1M tokens.
Get started with Windows and Office directly, and operate the computer with a large model agent
Link: https://news.miracleplus.com/share_link/18659
When we talk about the future of AI assistants, it’s hard not to think of the dazzling AI assistant Jarvis from the “Iron Man” series. Jarvis is not only Tony Stark’s right-hand man, but also his communicator with advanced technology. Today, the emergence of large models has subverted the way humans use tools, and we may be one step closer to such a science fiction scenario. Imagine if a multi-modal agent could directly control the computers around us through keyboard and mouse like humans, what an exciting breakthrough it would be. Recently, the School of Artificial Intelligence of Jilin University released the latest research “ScreenAgent: A Vision Language Model-driven Computer Control Agent” that uses a large visual language model to directly control computer GUIs, which maps this imagination into reality. This work proposed the ScreenAgent model, which for the first time explored the use of VLM Agent to directly control the computer mouse and keyboard without the need for auxiliary positioning tags, achieving the goal of directly operating the computer with large models. In addition, ScreenAgent achieves continuous control of the GUI interface for the first time through the automated process of “plan-execute-reflect”. This work is an exploration and innovation of human-computer interaction methods, and at the same time open source data sets, controllers, training codes, etc. with precise positioning information.
Revealing Sora’s technical roadmap: core members are from Berkeley, and the basic paper was rejected by CVPR
Link: https://news.miracleplus.com/share_link/18660
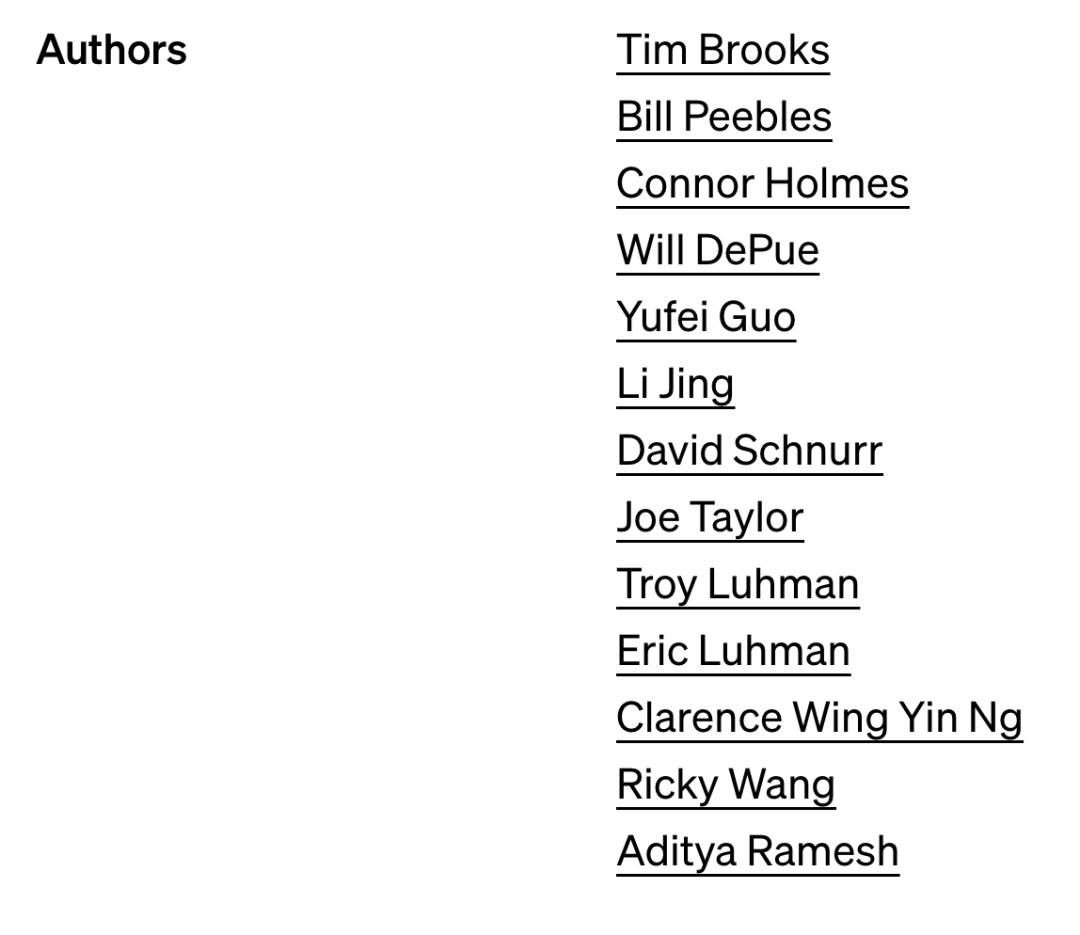
In recent days, it is said that Sora is being discussed at meetings of venture capital firms around the world. Since ChatGPT sparked a tech-wide arms race early last year, no one wants to be left behind on the new AI-generated video track. On this issue, people have long predicted, but also unexpectedly: AI generated video is the direction of continued technological development after text generation and image generation. Previously, many technology companies rushed to launch their own video generation technology. . However, when OpenAI released Sora, we immediately felt like “discovering a new world” – the effect was several levels higher than previous technologies. Among the participants of Sora this time, the known core members include R&D leaders Tim Brooks, William Peebles, system leader Connor Holmes, etc. The information of these members has also become the focus of attention.
Karpathy, who left OpenAI and was unemployed, started a new large-scale model project, and the number of stars exceeded 1,000 in a day.
Link: https://news.miracleplus.com/share_link/18661
OpenAI has been very lively in the past few days. First, AI guru Andrej Karpathy officially announced his resignation, and then the video generation model Sora shook the AI circle.
After announcing his departure from OpenAI, Karpathy tweeted, “I can take a break this week. However, eagle-eyed netizens discovered Karpathy’s new project-minbpe, which is dedicated to BPE (Byte Pair Encoding, word) commonly used in LLM word segmentation. Coding) algorithm creates minimal, clean, and educational code. In just one day, the project’s GitHub star has reached 1.2k.

Does Sora understand the physical world? A brainstorm is taking place among the big guys in the AI circle
Link: https://news.miracleplus.com/share_link/18662
Is Sora a physics engine or even a world model? Turing Award winner Yann LeCun, father of Keras Francois Chollet and others are discussing in depth. Unlike previous models that could only generate a few seconds of video, Sora suddenly extended the length of the generated video to 60 seconds. Moreover, it can not only understand the requirements put forward by users in Prompt, but also get the way people and objects exist in the physical world.

Financing exceeds US$1 billion, AI company “Dark Side of the Moon” receives new round of investment from Sequoia, Xiaohongshu, Meituan, and Alibaba
Link: https://news.miracleplus.com/share_link/18663
The AI startup “Dark Side of the Moon” has recently completed a new round of financing exceeding US$1 billion. Investors include Sequoia China, Xiaohongshu, Meituan, and Alibaba, and old shareholders also participated. Dark Side of the Moon’s last round of financing was over US$200 million in 2023, with investors including Sequoia China, Zhen Fund, etc. After this round of financing, the valuation of Dark Side of the Moon has reached approximately US$2.5 billion, making it one of the leading companies in the domestic large model field.

Zuckerberg’s latest conversation: Smartphones will not disappear, AR will be a mainstream mobile computing device, XR will be a desktop computing device, and generative AI will enable human-machine communication
Link: https://news.miracleplus.com/share_link/18664
Meta founder and CEO Mark Zuckerberg participated in an exclusive interview with Morning Brew last week. During the interview, Mark expressed his belief that AI and AR technologies will change the way we work, live and socialize in the future. Xiao Zha believes that AR smart glasses will be the next generation of computing mobile phones and computing platforms used on the road, while XR headsets may be the next generation of computer or TV screens. You will have a larger screen; for most people , the phone may be the more important device, and the glasses may become the more important and ubiquitous thing, but they both make sense.

Sora proves Musk was right, but Tesla and humanity may have lost
Link: https://news.miracleplus.com/share_link/18665
Sora launch, Musk may be the one with the most complicated emotions. Not only because of his own early entanglements with OpenAI, but also because Sora is actually realizing the direction that Tesla has been exploring in the past few years. On February 18, Musk left a message under a video titled “OpenAI’s bombshell confirms Tesla’s theory” by technology anchor @Dr.KnowItAll, saying “Tesla has been able to use precise physical principles to create real-world The video is about a year old.” He then forwarded a 2023 video on X, in which Ashok Elluswamy, Tesla’s director of autonomous driving, introduced how Tesla uses AI to simulate real-world driving. In the video, AI generated seven driving videos from different angles at the same time. At the same time, you only need to input instructions such as “go straight” or “change lanes” to make these seven videos change simultaneously.

NVIDIA reveals for the first time currently the fastest AI supercomputer: equipped with 4608 H100 GPUs
Link: https://news.miracleplus.com/share_link/18666
Recently, NVIDIA announced to the outside world for the first time its latest enterprise-oriented AI supercomputer Eos, which is also NVIDIA’s fastest AI supercomputer. According to reports, Eos is equipped with a total of 4,608 Nvidia H100 GPUs and 1,152 Intel Xeon Platinum 8480C processors (each CPU has 56 cores). Eos also uses NVIDIA Mellanox Quantum-2 InfiniBand technology, with data transmission speeds up to 400 Gb/s, which is crucial for training large AI models and system expansion.
